What Does The Trump Say?
推特(Twitter)作为一个全球流行的网络社交平台,类似于墙内的微博,数以亿计的用户在上面分享信息(tweets)。

唐纳德·特朗普(Donald Trump)与美国的主流媒体关系紧张,他无法通过这些媒体来传播自己的声音。那就只好亲自上阵,在推特上发表自己的政见和各种喜怒哀乐。也正因为他当上了美国总统,他的推特一经发出,就会立即传遍全世界,正所谓“推特治国”。这比报纸报道和电视做节目快多了,而且更直接,更准确,也更具有分析价值。
特朗普的推特主要有以下几个特点:
本文通过Trump 2009~2018 的推文数据来看看川普这个人和那些事。文中仅展示主要代码,你可以到我的GitHub上查看更多细节。
第一步是寻找更多更新的特朗普推特的数据集。
Twitter提供了官方的API供用户用python语言与客户端交互,我们可以用它获取到所需要的数据,具体方法参见推特API说明文档。但是,官方API有限制,我想要的是特朗普的的全部tweets,因此放弃这个方法。 但是还是可以利用它搞事情,关于Twitter API,你可以到我的Github看看。
好在我发现了一个很棒的 Trump Twitter Archive ,作者是 Brendan Brown。里面提供了特朗普自2009年至今的tweets,而且持续更新!我们可以利用Python很轻松地拿到所需数据:
import requests
import json
def get_tweets(year):
# the truly excellent Trump Twitter Archive, which contains all of Trump’s tweets going back to 2009.
url = ('http://www.trumptwitterarchive.com/data/realdonaldtrump/%s.json' %year)
r = requests.get(url)
print(str(year) + ' --> ' + 'done.')
return r.json()
def save_tweets(years=range(2009,2019)):
tweets = []
for y in years:
data = get_tweets(y)
dl = len(data)
i = 0
while i < dl:
tweets.append(data[i])
i += 1
return tweets
with open("trump_tweets_2009~2018.json", "w") as outfile:
json.dump(save_tweets(), outfile)
print('ok')
截至数据抓取时,共包含33042条数据。
import pandas as pd
df = pd.read_json('trump_tweets_2009~2018.json')
df.shape # (33042, 8)
其中包括了 created_at、favorite_count、is_retweet、retweet_count、source和text 等维度属性。
tweets维度属性介绍:
| 维度 | 说明 |
|---|---|
| text | the text of the tweet itself |
| created_at | the date of creation |
| favorite_count、retweet_count | : the number of favourites and retweets |
| is_retweet | : boolean stating whether the authenticated user retweeted this tweet |
| id_str | the tweet identifier |
| in_reply_to_user_id | user identifier if the tweet is a reply to a specific user |
接下来对tweets的文本也就是text(utf-8编码)进行预处理。
跟微博类似,twitter文本具有一些特殊的语法:
https,这个token辨识为网站链接(link)RT,则该token为转发的tweet(retweet)的固定开头@,则为推特的用户名#,则代表hashtag(twitter中用来标注线索主题的标签)&,则基本上是tweet中的&符号,在utf-8的文本中为&这里利用NLTK模块中的TweetTokenizer分词器来清理文本。当然,你也可以用正则表达式筛选。
# use TweetTokenizer to tokenise a Tweet Text
from nltk.tokenize import TweetTokenizer
tknzr = TweetTokenizer()
def tokenizer_tweets(df):
text = ''
for t in df['text']:
text += t
tokens = [i.lower() for i in tknzr.tokenize(text)]
return tokens
tokens = tokenizer_tweets(df)
print(len(tokens))
print(tokens[:20])
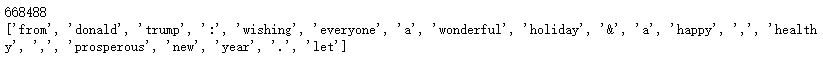
去除特殊语法和停用词:
# remove stop words and other noise(links and special characters) to get clear tokens
from nltk.corpus import stopwords
import string
punctiuation = list(string.punctuation)
stop = stopwords.words('english') + punctiuation
def clear_tokens(tokens):
tokens_cl = [t for t in tokens if (len(t) >= 3)
and (not t.startswith(('#', '@')))
and (not t.startswith('http'))
and (t not in stop)
and (t[0].isalpha())]
return tokens_cl
tokens_cl = clear_tokens(tokens)
print(len(tokens_cl))
print(tokens_cl[:20])

数据清洗完成之后,我们可以进行一些基本的分析了 先来看看特朗普推特里最常@的人和最常用的标签吧!
# top 10 mentions
from nltk import FreqDist
mentions = [t for t in tokens if t.startswith('@')]
mentions_fd = FreqDist(mentions).most_common(10)
# top 10 hashtags
hashtags = [t for t in tokens if (t.startswith('#') and len(t) != 1)]
hashtags_fd = FreqDist(hashtags).most_common(10)

特朗普多与政客和新闻媒体“互动”

特朗普的标签大多是竞选口号
tweets的平均长度:
# extract the mean of lenghts:
import numpy as np
mean = np.mean([len(i) for i in df.text])
print("The lenght's average in tweets: %.2f%%" % mean)
# The lenght's average in tweets: 110.91%
要知道一条推文最多发140字,特朗普每条推文平均110字,他很喜欢发大段文字的推文。
最多likes和转发的tweet:
# extract the tweet with more FAVs and more RTs:
fav_max = np.max(df['favorite_count'])
rt_max = np.max(df['retweet_count'])
fav = df[df.favorite_count == fav_max].index[0]
rt = df[df.retweet_count == rt_max].index[0]
# Max FAVs:
print("The tweet with more likes is: \n{}".format(df['text'][fav]))
print("Number of likes: {}".format(fav_max))
print()
# Max RTs:
print("The tweet with more retweets is: \n{}".format(df['text'][rt]))
print("Number of retweets: {}".format(rt_max))
特朗普在当选当晚发的感谢推文收到了最多的likes,而讽刺CNN的推文则得到了最多的转发

再来看看likes和RTs的时间序列:
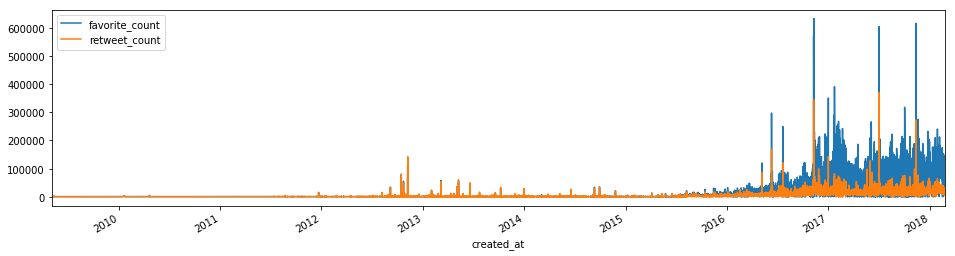
特朗普在2016年前在推特上并没有受到太大的关注,而在2016年11月成功当选美国总统后就不一样了。
特朗普在一天中的什么时候发推呢?
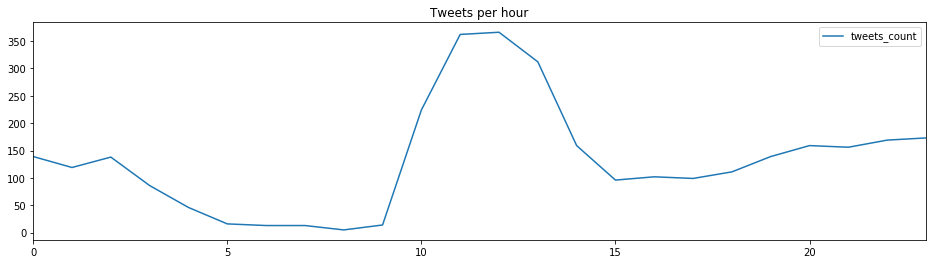
在上任后,特朗普的推文较常集中在9时至午间时段,在晚间也有小幅增长。 整体上看符合他的生活规律,但要知道的是特朗普的推特可不只有他一人在使用,还有他背后的团队在运作。 而他本人和团队所使用的设备是不同的,特朗普使用安卓设备,而他的团队出于安全性的原因使用的是苹果手机。 特朗普用过以下平台发推:
# obtain all possible sources:
sources = list({source for source in df['source']})
# print sources list:
print("Creation of content sources:")
for source in sources:
print("* {}".format(source))
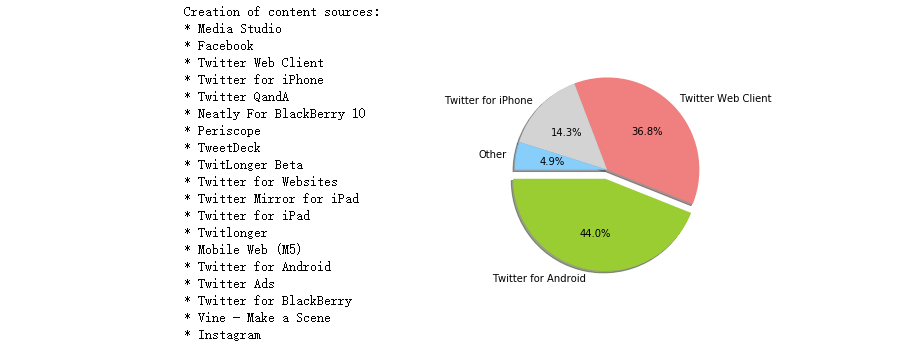
需要注意的是,特朗普地推特在2015年6月宣布竞选后才开始较多地使用苹果手机发布推文,而在2017年3月后特朗普便停止使用安卓设备:
不仅在发推设备上有差异,他本人和团队的发推风格也是不同的,这点在后面的分析中会讲到。
让我们先利用前面清理推文得到的tokens来画个词云看看特朗普推文中较常出现的词汇吧!
# use the tokens of original tweets to draw a wordcloud
df_original = df[~df.is_retweet].copy()
df_original.index = df_original.created_at
# after Trump formally announced his candidacy
tokens_original = clear_tokens(tokenizer_tweets(df_original['2015-6':'2018']))
print(len(tokens_original)) # 94213
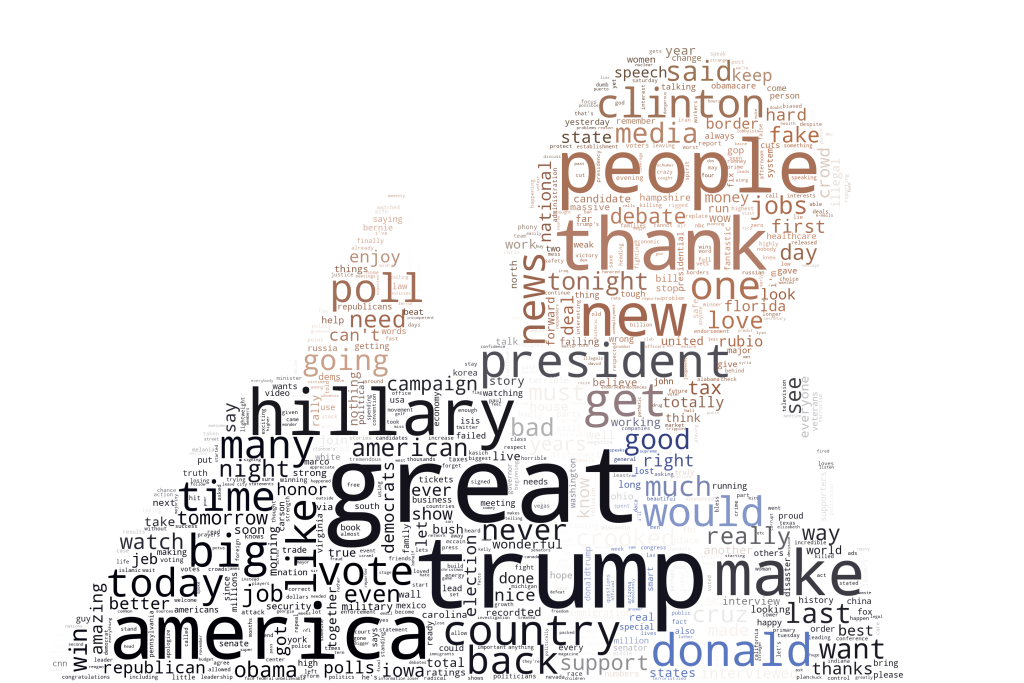
看起来还不错,符合我们对特朗普的印象。。。 再来看看推文中最常出现的bigrams(二元语法,两个单词组成的词语)的频率:
import nltk
from nltk.collocations import *
#Create bigrams
bgs = nltk.bigrams(tokens_original)
#compute frequency distribution for all the bigrams in the text
fdist = nltk.FreqDist(bgs)
bigram_fq = fdist.most_common()
bigram_fq_25 = {k:v for k,v in dict(bigram_fq[:25]).items()}
因为特朗普与媒体关系紧张的原因,Fake News也是一个经常在他的推文中出现的词语。当然,你也可以看到crooked和hillary几乎是如影随形。 那么再来看看特朗普关于希拉里的推文出现的频率吧:
希拉里早期作为奥巴马的幕僚也时而会被特朗普连骂,而在2015年4月希拉里宣布竞选后被提起的频率一路飙升,即使在落败后,也因为早年的电邮门被特朗普“念念不忘”。
特朗普本人发推较少使用表情、链接(视频和图片也是链接的一种)和标签,就连转发也是复制推文用双引号括起来:
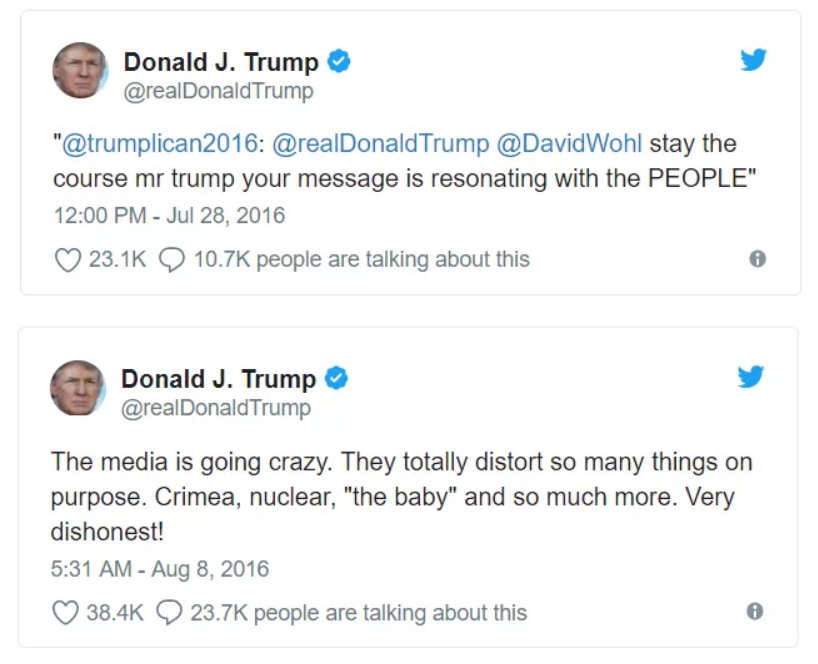
而团队的推文则相反,通常是图文并茂,且通常是事务性、祝贺性的推文,文风较为温和:
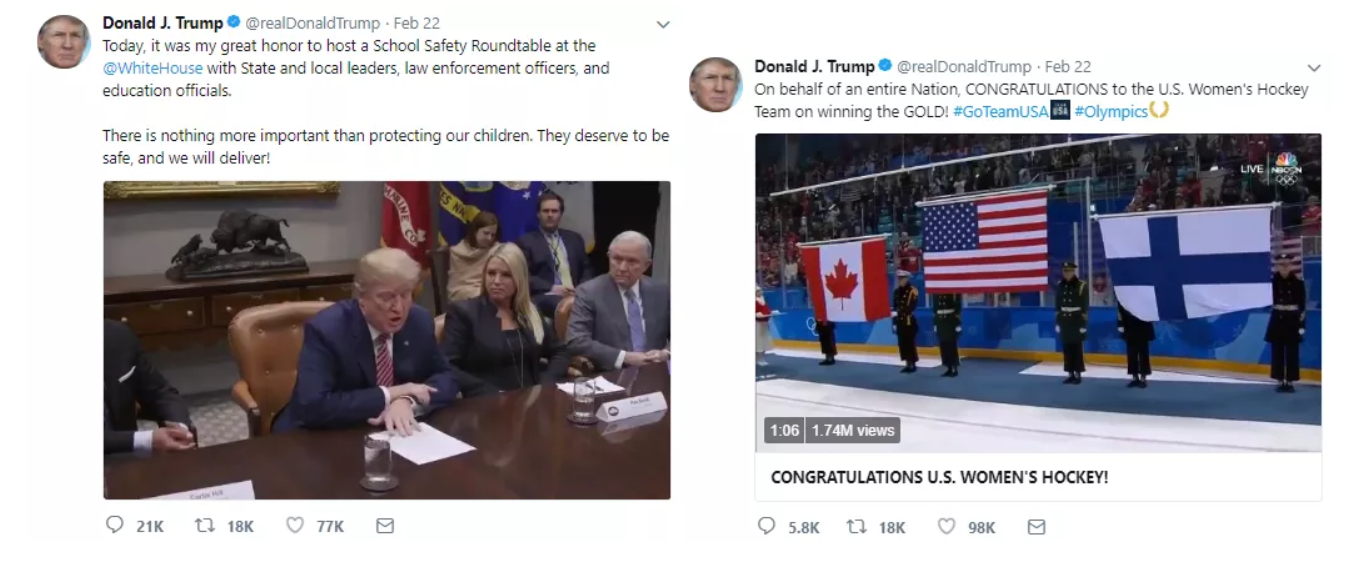
可以看到在links和quotes上两者存在较大差距,这也是判断推文发布者的条件之一:
是爱是恨,用textblob一探便知。
# textblob will allow us to do sentiment analysis in a very simple way
from textblob import TextBlob
import re
def clean_tweet(tweet):
'''
Function to clean the text in a tweet by removing links and special characters using regex.
'''
return ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
def get_tweet_sentiment(tweet):
#Function to classify sentiments of passed tweets using TextBlob's sentiment method
analysis = TextBlob(clean_tweet(tweet))
#set sentiments
if analysis.sentiment.polarity > 0:
return 'Positive'
elif analysis.sentiment.polarity == 0:
return 'Neutral'
else:
return 'Negative'
textblob是在NLTK之上构建的,可以轻松实现一些简单的NLP任务如词类标注和情感分析等。 这里利用textblob简单实现了推文的情感分析,但如果要让结果更加精准的话,还是要自己去训练模型。
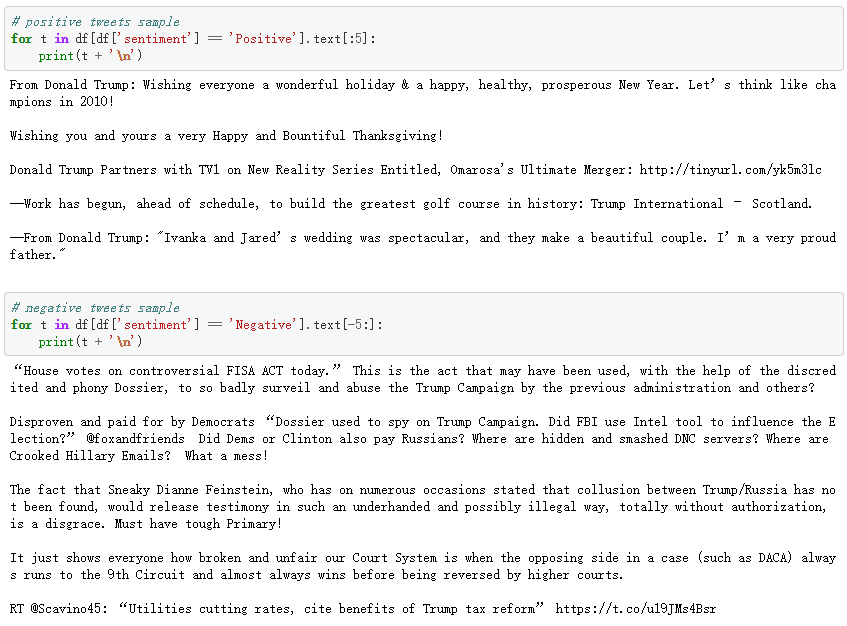
积极的推文居多:
# print percentages:
pos_tweets = df[(~df.is_retweet) & (df.sentiment == 'Positive')]
neu_tweets = df[(~df.is_retweet) & (df.sentiment == 'Neutral')]
neg_tweets = df[(~df.is_retweet) & (df.sentiment == 'Negative')]
print("Percentage of positive tweets: %.2f%%" %(len(pos_tweets)*100/len(df[(~df.is_retweet)])))
print("Percentage of neutral tweets: %.2f%%" %(len(neu_tweets)*100/len(df[(~df.is_retweet)])))
print("Percentage of negative tweets: %.2f%%" %(len(neg_tweets)*100/len(df[(~df.is_retweet)])))
# Percentage of positive tweets: 56.09%
# Percentage of neutral tweets: 27.21%
# Percentage of negative tweets: 16.70%
在情感分析的基础上来画出积极和消极词汇的词云:
# draw a positive wordcloud and a negative wordcloud
pos_tokens = [t for t in tokens_original if get_tweet_sentiment(t) == 'Positive']
neg_tokens = [t for t in tokens_original if get_tweet_sentiment(t) == 'Negative']
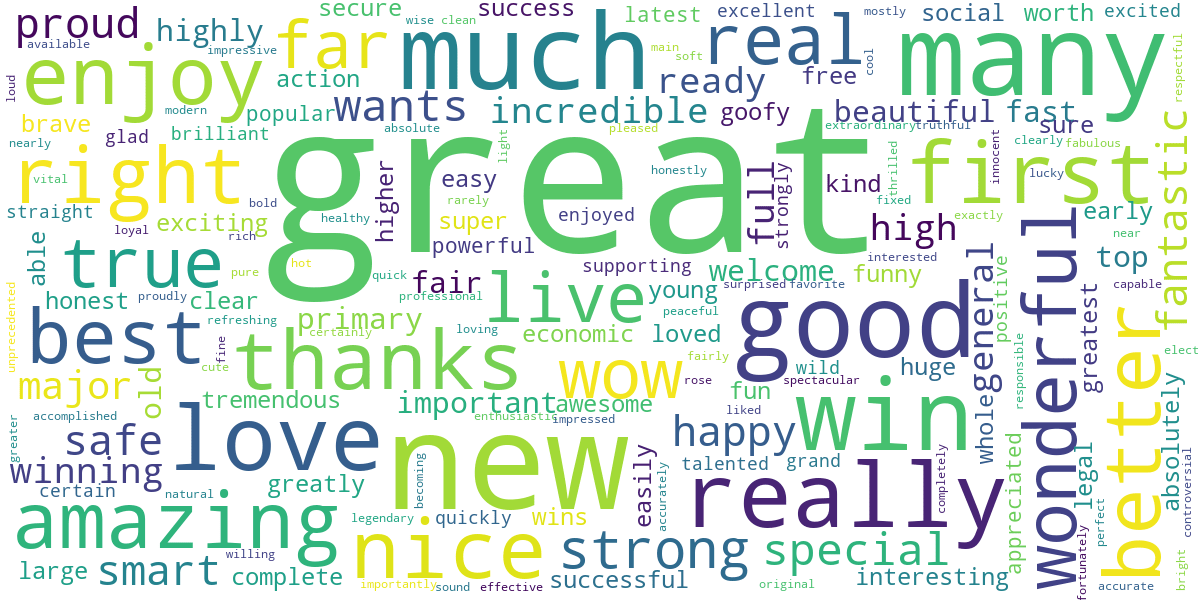
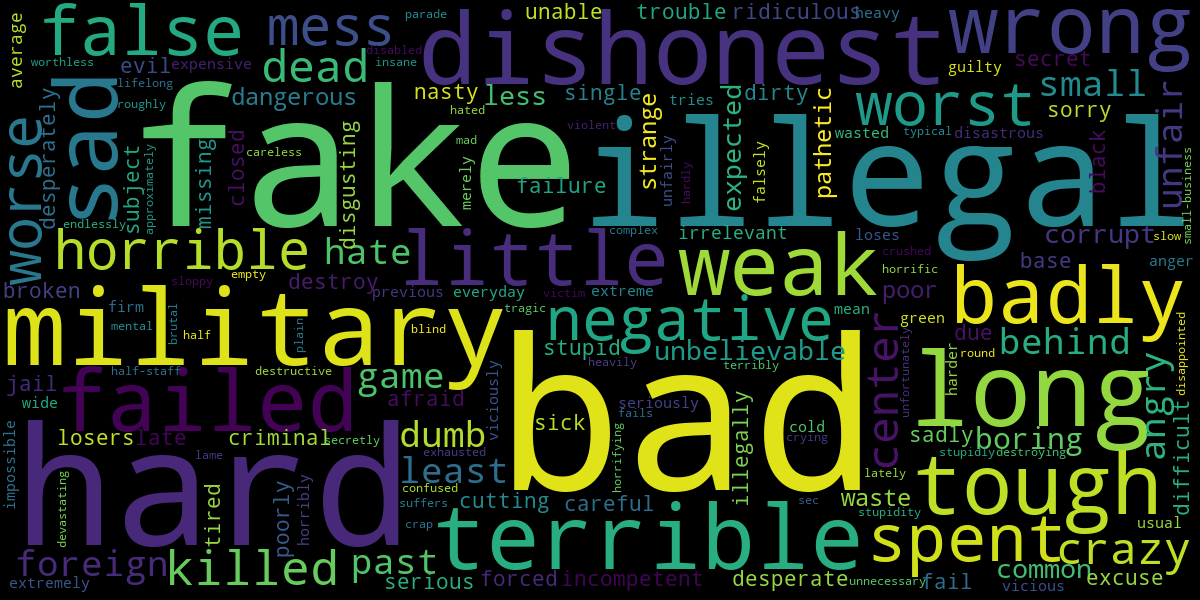
可以看出,特朗普的推文中较少出现高级词汇,大多都是很口语化的表达,包括他的演讲或采访。
前面说到,特朗普团队使用苹果手机发推,而他本人在2017年3月前使用安卓发推,不同设备上的推文情感是不同的:
可以看到在他停止使用安卓手机之后,苹果手机的消极推文有较大的上升趋势。
特朗普的推特就是他的宣传阵地,反传统的他“推特治国”、敢爱敢恨、畅所欲言,各种怼美国传统主流媒体和看不惯的人事物,因为他自己一发推文便传遍世界,影响力巨大。他一天发推频繁,推文发布在不同平台上,也有员工在运作,以至于推文风格在不同平台上出现了较大的反差。 可以说,特朗普的个人风格十分明显,在推特上和现实中无差,可能这就是他在其他主流精英中突出的原因吧。 最后以一个挺有趣的视频收尾:How (And Why) Donald Trump Tweets
